Histogram A very common tool for data exploration is histogram, which provides a clear visualization of the distribution of a dataset. It can be viewed as a discrete approximation of the underlying probability density function (PDF) of the data.
KDE Kernel Density Estimation (KDE), on the other hand, provides a smooth estimate of the PDF of the …
Posts
18 pages
Articles
“Heuristic” 这个词在英文中有两个近似的含义, 根据 Oxford Dictionary 的定义, 第一个意思是: “Enabling a person to discover or learn something for themselves.” 这个意思对应于中文中的 “启发式” 主要用在教育的语境中, 例如 “启发式教学”, 这是一种教学方法, 强调在教学时教师引导学生主动学习而不只是被动地接受, 学生在老师的引导下自己发现要学习的知识.
在这个意思之下还有另一个意思, 有 Computer 标签, 因此算是计算机领域的术语, 意思是: “proceeding to a …

Data Preparation The dataset contains information on the finals of the Australia Open over the years, with each row representing one match. The information includes year of the match, gender, champion’s name, champion’s nationality, score details, champion’s seed, runner-up’s name, runner-up’s nationality, and …
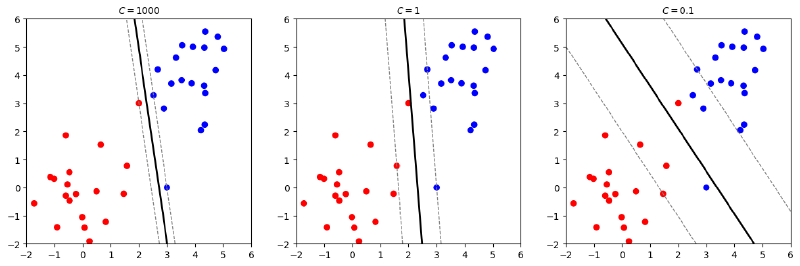
A Study on Support Vector Machines
This article thoroughly explores the principles, implementation, and applications of Support Vector Machines (SVMs). It introduces three methods of implementing SVMs, including solving the dual problem using a QP solver, SMO and Gradient Descent. The dataset used for experiment is the MNIST dataset.
座位问题 设想一个房间中有 10 把椅子, 现在有 6 个人准备随机地在房间中选择一把椅子落座。已知有 4 把椅子在前排, 求前排椅子被坐满的概率。
方法一:排列视角 一种思路是将这个问题看成是一个排列问题, 即考虑每个人落座的顺序。那么样本空间的大小(Total number of outcomes)为:
$$ {}_{10}P_{6} $$下面只要计算在所有这些情况中, 满足"前排 4 把椅子被坐满"这一条件的排列数即可。
可以认为有 3 个步骤:
从 6 个人中随机抽取 4 个人, 有 \(\binom{6}{4}\) 种可能。 将这 4 个人安排到前排的 4 把椅子上, 共有 \(4!\) 种排列。 待这 4 个人选定之后, 剩下的 2 个人从剩下的 6 把椅子中 …
Reboot to Windows Once from Linux On a dual-boot machine, you may occasionally want to reboot into Windows from Linux for a specific task—such as using a Windows-only application—and then return to Linux afterward. While GRUB allows you to choose which OS to boot, it is more convenient to have a one-time reboot option that boots directly into …
epoch train_loss valid_loss error_rate time 0 1.497884 0.302666 0.087280 01:02 epoch train_loss valid_loss error_rate time 0 0.494630 0.309310 0.099459 01:04 1 0.310687 0.254076 0.084574 01:06 epoch train_loss valid_loss error_rate time 0 1.330929 0.305042 0.089986 01:07 epoch train_loss valid_loss error_rate time 0 0.523440 0.362486 0.104871 …
Deep Learning for Coder: Chapter 4
This article is a learning note based on the book "Deep Learning for Coders with fastai and PyTorch" by Jeremy Howard and Sylvain Gugger. It covers key concepts from Chapter 4, ranging from non-parametric methods, linear functions, SGD, optimizers, learners, nonlinearity to deeper networks.
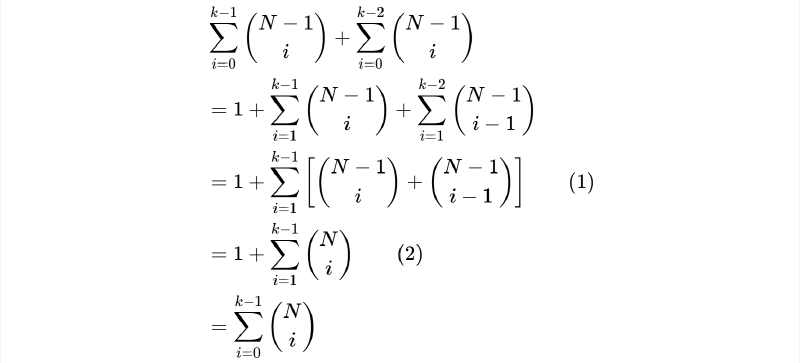
The Theory of Generalization: From Break Points To The Vc Inequality
This article discusses the theory of generalization in machine learning, focusing on concepts such as break points and the VC inequality. This is a learning note based on a machine learning course from caltech.
问题的定义 定义: 假如两个运动员 A 和 B 相约通过投篮的方式分出胜负, 规则是: 一人投一次, 率先投进的人获胜. 如果 A 和 B 两人投篮时所站的位置相同, 并且每次命中的概率分别是 \(p\) 和 \(q\), 如果 A 先投, 那么他获胜的概率是多少?
澄清: 假设运动员每次投篮的概率都相等, 并且周围的环境不会对他造成任何影响.
解决这个问题涉及到几何级数: \(\text{if } r\in R \text{ and } |r|<1\text{ then:}\) $$\sum_{n=0}^{\infty}{r^n}=1+r+r^2+r^3+\cdots=\frac{1}{1-r}$$解决方法 假如 A 第一次投篮就投中, 显然这个事件的概率是 \(p\). 而 A 在第二次 …
A Study On Logistic Regression
This article introduces and explore a classic machine learning algorithm, Logistic Regression.
A Study on the Birthday Problem
本文介绍了生日问题, 包括问题的定义, 极端情况, 穷举法, 对立事件的概率以及 Python 模拟. 本文是对<普林斯顿概率论>一书中相关内容的学习笔记.
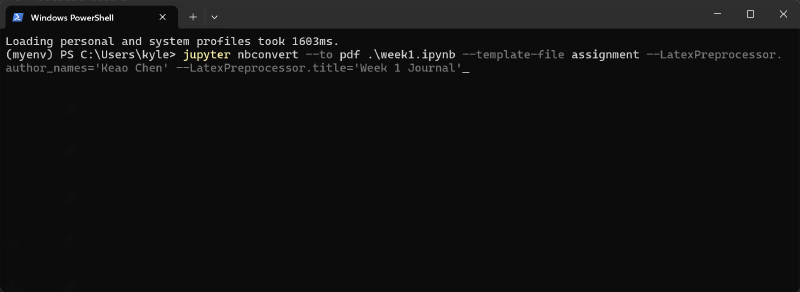
Install nbconvert via pip
Now, the command
should work well, producing a document with a table of contents and properly formatted code blocks. However, an unnecessary counter appears before each code block, wasting space and serving no purpose. To remove it, a custom template is required.
The template consists of two files: assignment.tex.j2 and …
exporting all selected notes with media references extract media paths from the exported file write a python script merging all selected audios into one
Introduction Dictionaries such as “Oxford” and “Longman” are used as the sources for the definitions in my flashcards. However, they sometimes contain too much unnecessary information, therefore making it unwieldy and grandiose, leading to a low loading speed and distractions.
Since an MDX file utilizes the HTML format to …
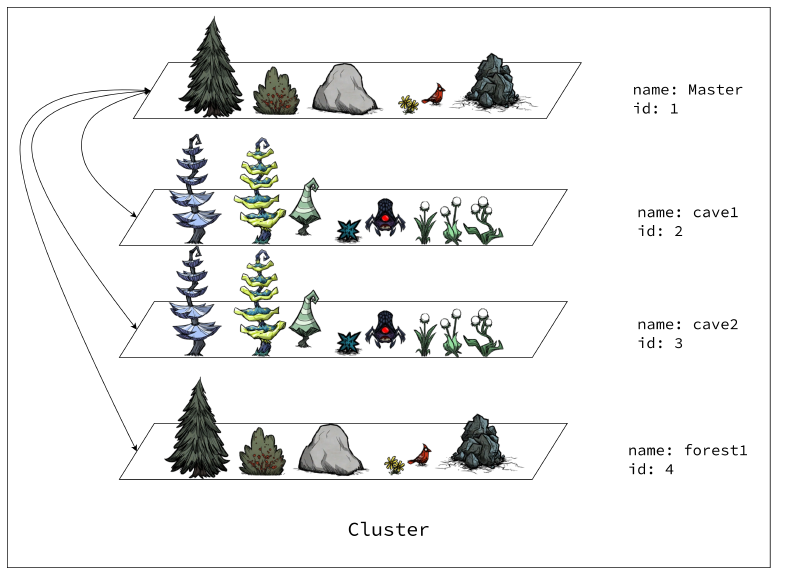
饥荒联机版专用服务器和多层世界配置指南
本文介绍了如何在本地或云服务器上搭建饥荒联机版专用服务器 (Don't Starve Together Dedicated Server),并配置多层世界。内容包括存档文件的准备、模组的配置以及常见问题的解决方法。本文优化了官方提供服务器启动的脚本, 使其可以自动处理模组的配置, 免去了手动配置的麻烦.
Android QQ 的图片文件是以下面这种结构保存的,以Cache_开头的文件就是图片。这种结构在浏览时要分别点进每个文件夹才能看到图片,很不方便。
使用 GNU Parallel 配合mv可以快速的 “解散” 每个二级文件夹,变成以下这种结构。
命令如下:
参考: https://www.myfreax.com/gnu-parallel/
shell 脚本是处理这类工作最为简单,快捷的方式。
修改后缀 格式转换 heic 转 jpg 首先,安装转换工具。
然后可以使用 heif-convert 命令转换。
批量转换,命令如下。
这条命令的原理是:根据当前文件夹下的 .heic 文件生成 .jpg 文件,如果成功生成则删除原 .heic 文件,如果未成功则不会删除原文件。 此外,如果未能生成 .jpg 文件的原因是 Input file 'filename.heic' is a JPEG image ,那么可以使用批量修改后缀的方法直接将文件的后缀改为 .jpg。
flac 转 mp3 首先,安装转换工具:
然后可以使用 ffmpeg 命令转换,除了格式转换,ffmpeg 还支持很多功能,具体可以查阅文档。
批量转换,命令如下: …